Contributing knowledge to open-source LLMs like the Granite models using the InstructLab UI
By Ahmed Azraq
Large Language Models (LLMs) have immense potential, but they come with challenges like the need for high-quality training data, specialized skills, and extensive computing resources. Forking and retraining these models can be time-consuming and costly. That’s where InstructLab steps in! This open-source project leverages community contributions to enhance LLMs, offering a more efficient and collaborative approach to generative AI.
| The "lab" in InstructLab stands for Large-Scale Alignment for ChatBots, which is detailed in the LAB: Large-Scale Alignment for ChatBots research paper. InstructLab is a community-based approach to building truly open-source LLMs. The InstructLab community model will be updated with a periodic release cycle for models and data shared regularly on Hugging Face. Learn more about what InstructLab is and why developers need it in this article on IBM Developer. |
In my previous tutorial, Contributing knowledge to the open source Granite model using InstructLab, I showed how to set up your local environment, and locally run the entire process of fine-tuning and contributing to open-source LLMs, such as IBM Granite. The end-to-end process included updating the taxonomy and dealing with YAML files, which required expertise with YAML and familiarity with the GitHub pull request (PR) process.
In this tutorial, you learn how to accomplish the same goal of fine-tuning open-source LLMs using InstructLab UI. The InstructLab User Interface (UI) allows you to easily contribute knowledge or skills to the InstructLab taxonomy repository without worrying about YAML structure, the different validation rules, or the GitHub pull request (PR) process.
The InstructLab UI enables users to focus on enhancing the open-source LLM’s capabilities without needing to worry about the tools and processes and allow them to focus on the content of the contribution. This intuitive UI can be used by a wide spectrum of users ranging from GitHub and YAML savvy developers to those who do not have any familiarity with these tools.
Prerequisites
-
You must have a GitHub account.
-
Important: Make sure that you populate your name in your GitHub account by editing the name field here. This GitHub name field is required to populate the name field in InstructLab UI.
-
Make sure to uncheck Keep my email addresses private in your GitHub account here. This setting is required to populate the email field in InstructLab UI.
-
To fine tune the model locally, check the Requirements section of the InstructLab documentation for the operating system, hardware, and software prerequisites.
Steps
Step 1. Gain access to InstructLab UI
InstructLab UI is currently released as a beta version. To access the UI, you must request access through performing the steps in this section. The steps in this section need to be done only the first time you are accessing the InstructLab UI.
-
Open InstructLab UI, and click Sign in with GitHub.
-
On the GitHub login page, login with your user name and password.
-
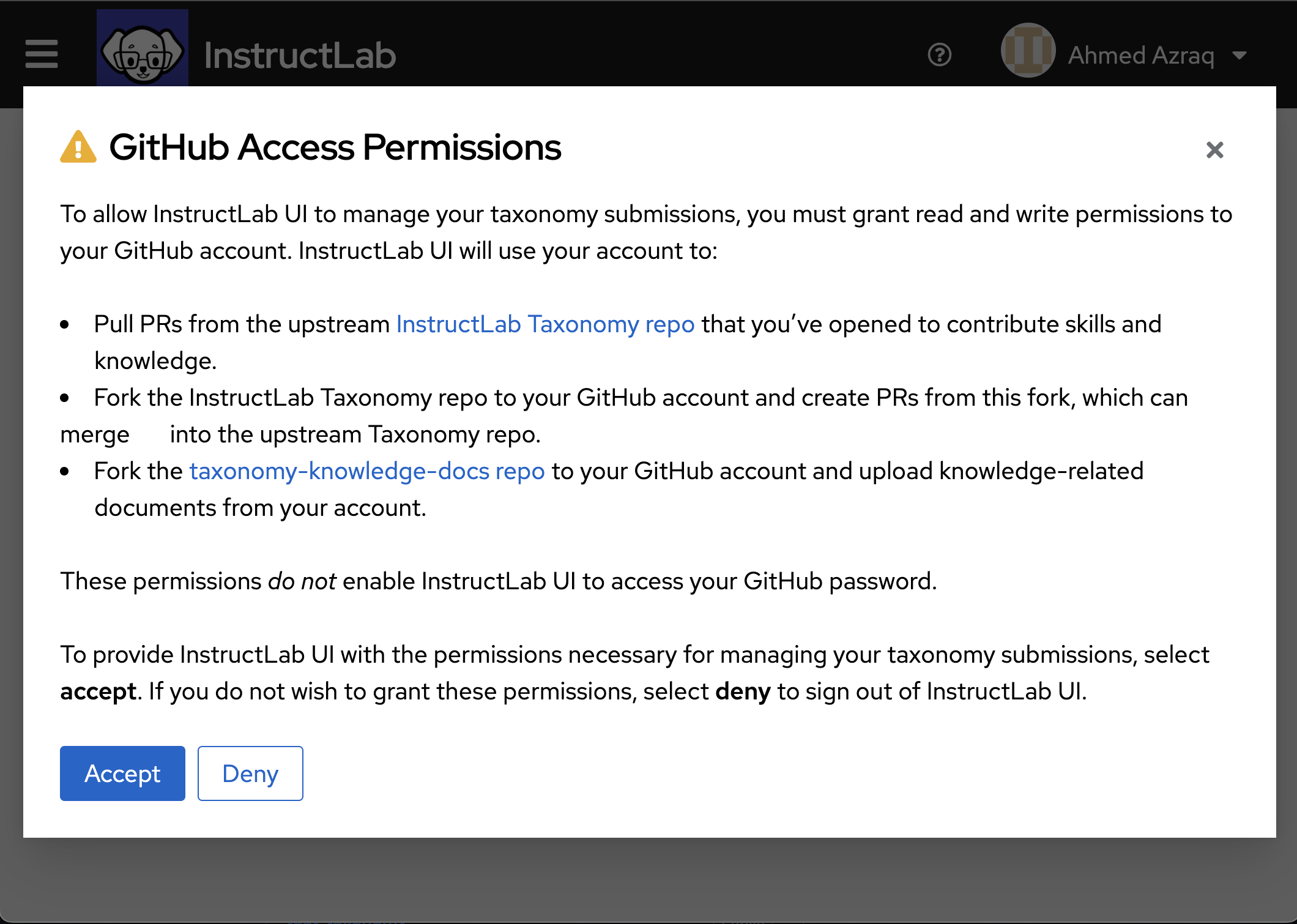
You must authorize InstructLab UI to be able to access your GitHub account. This is required because InstructLab UI allows you to pull PRs, fork the repositories, and submit PRs directly. Click Authorize instructlab-public.
-
You must be part of the instructlab-public GitHub organization to be able to access InstructLab UI. You can self-invite yourself. Once you login with your GitHub account, InstructLab UI will detect that you are not part of instructlab-public organization, and it will show a pop-up that has a button to self-invite to the organization. Click Send Invite.
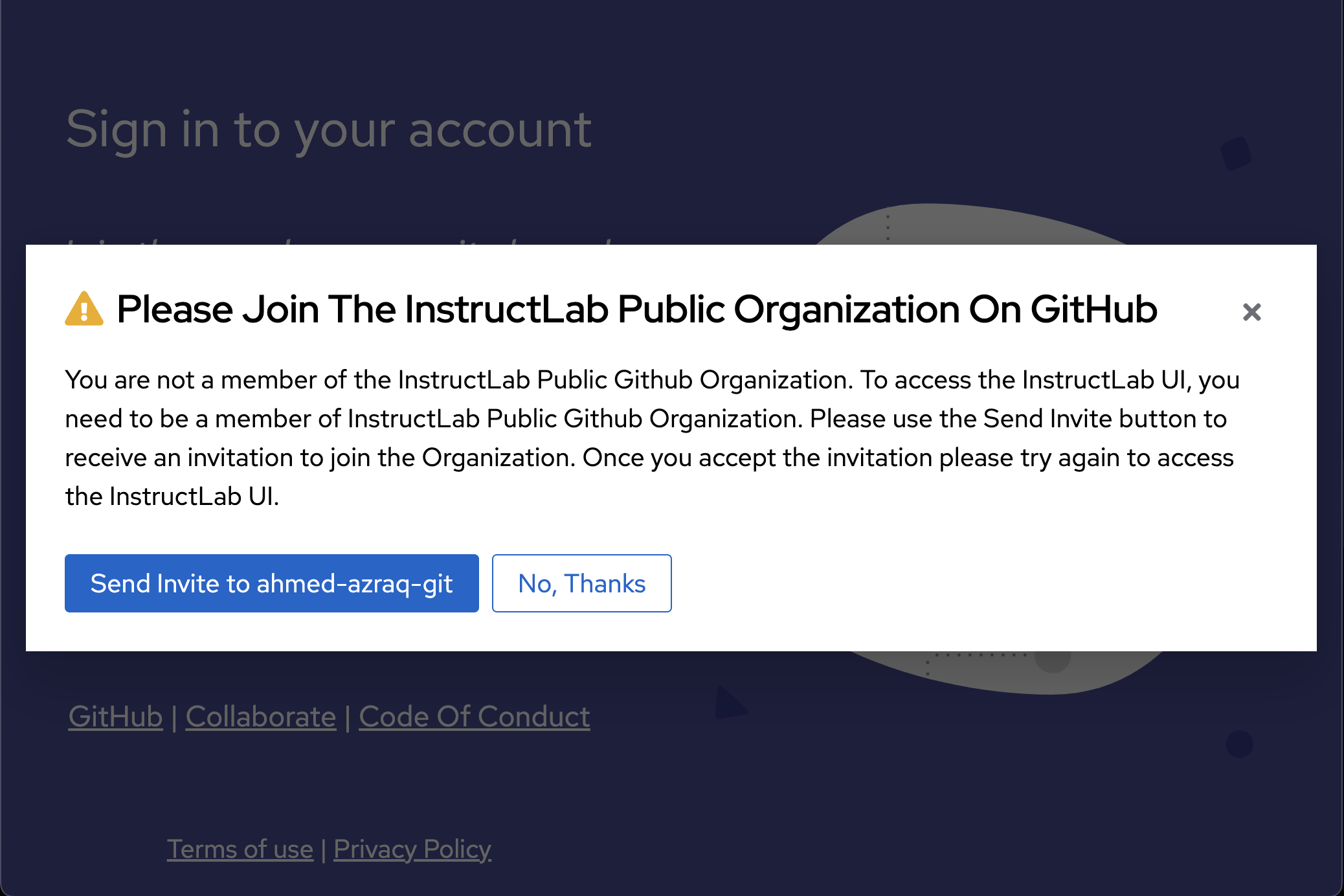
-
Check your email, you should receive an email from GitHub with the organization invitation. Click Join @instructlab-public to join the organization.
-
On the GitHub UI, click Join InstructLab Public Users to accept the organization invitation.
-
Now, you should be able to access InstructLab UI. On the InstructLab UI Login Page, click Sign in with GitHub.
-
Accept the GitHub access permissions. Click Accept.
Step 2. Chat with the model
In this section, you are going to chat with the current LLM to see if the model is already trained on the knowledge or skill that you want to contribute or not.
InstructLab UI allows you to chat with these two models (as of the time of writing this tutorial):
-
Granite-7b: Open-source IBM Granite model.
-
Merlinite-7b: Derivative model from Mistral-7b, trained with the LAB method.
Additionally, you can chat with your own served model by adding its endpoint in Custom Model Endpoints in InstructLab UI.
To chat with the model, follow these steps:
-
Open InstructLab UI
-
Navigate to Playground > Chat.
-
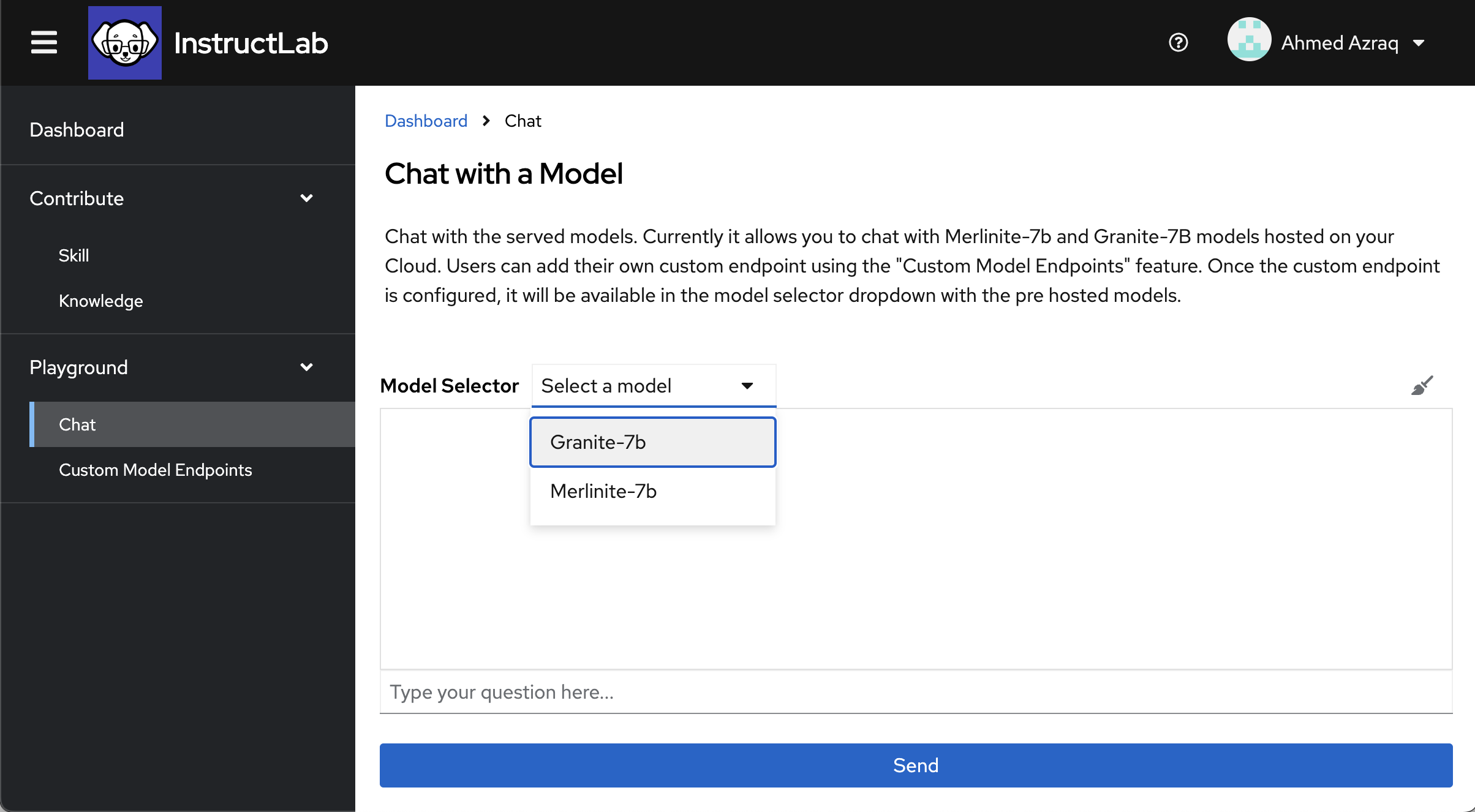
In the Model Selector, select the model you want to chat with. Select Granite-7B from the drop-down list.
-
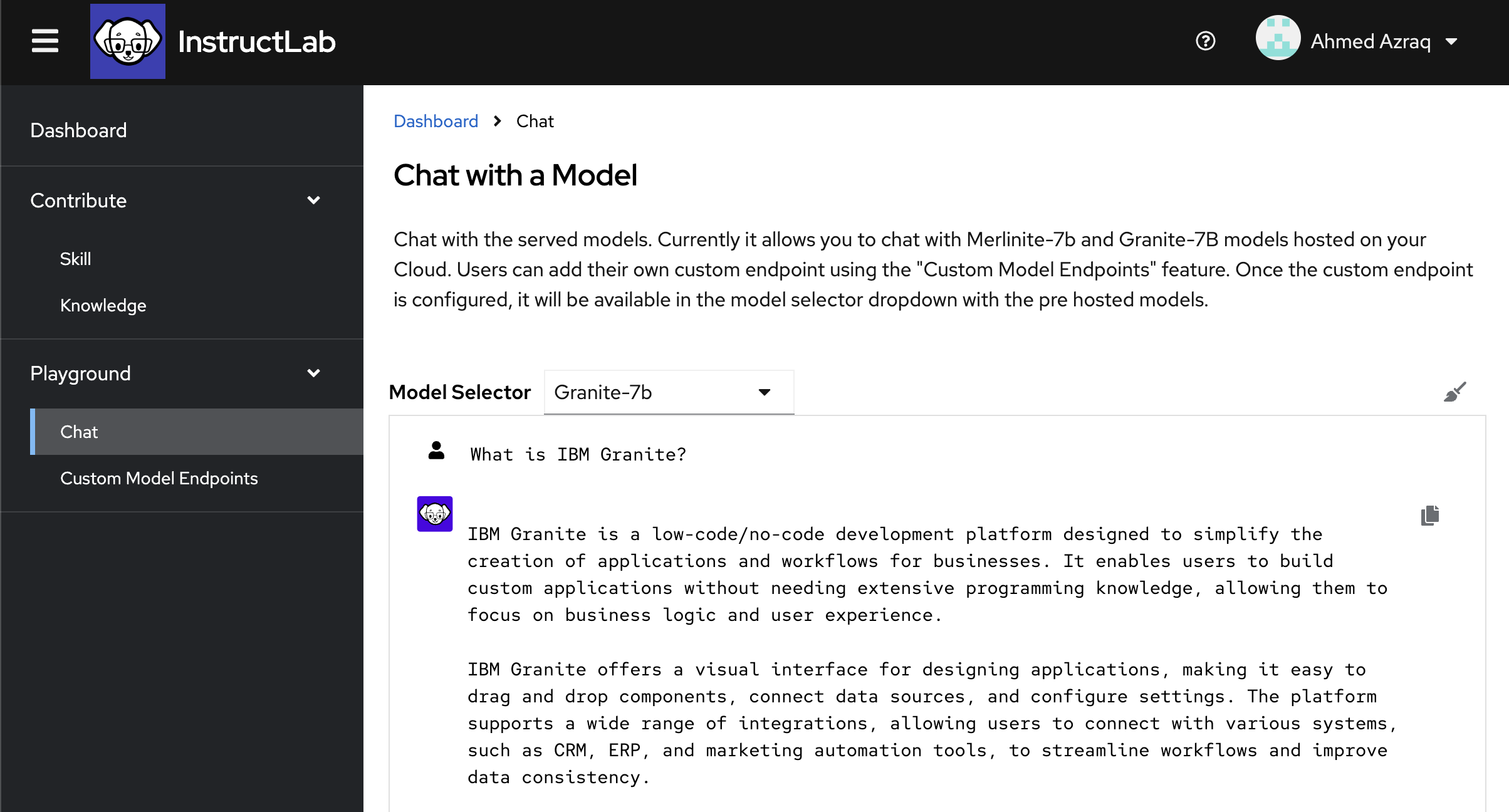
Type What is IBM Granite, and then click Send.
-
The IBM Granite model is not yet trained on the knowledge about IBM Granite. The existing model didn’t identify that IBM Granite is a foundation model. The model in this case is hallucinating, so you might receive different results.
In the next steps, you learn how to fine tune an open-source LLM (IBM Granite) with additional knowledge.
Step 3. Prepare the new knowledge as a Markdown file
In this step, you’ll create a Markdown file including the new knowledge. This is the source knowledge file: IBM Granite from Wikipedia.
-
Convert the Wikipedia article into Markdown format. Try to make the MD file readable, clean, and do not use Markdown table formats.
-
Save the Markdown file locally with the .md extension, for example: IBM-Granite.md.
Step 4. Add the new knowledge to the taxonomy
InstructLab uses a synthetic-data-based alignment tuning method for LLMs. InstructLab is driven by carefully created taxonomies, built into a taxonomy tree. The taxonomy allows you to train models tuned with your additional skills or knowledge.
InstructLab UI does extensive validation to make sure that the submissions confirms to all the standards.
-
In InstructLab UI, navigate to Contribute > Knowledge.
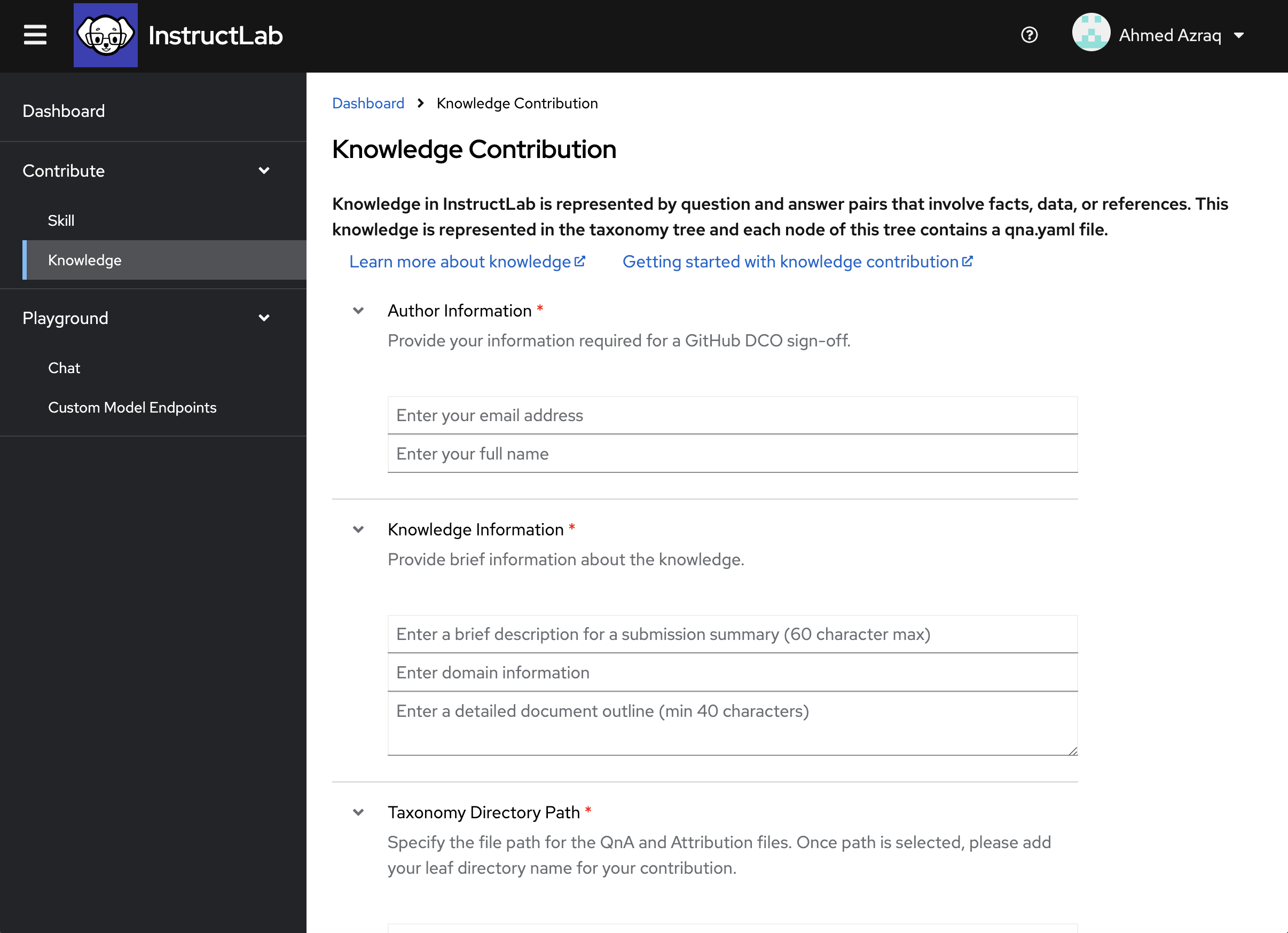
-
Enter the author information. This information is required when submitting your change as a pull-request on the upstream for GitHub DCO (Developer Certificate of Origin). Ensure that you use the same name and email address that is associated with your GitHub account. In the email field, try to put an invalid email format, and note that InstructLab UI prevents that.
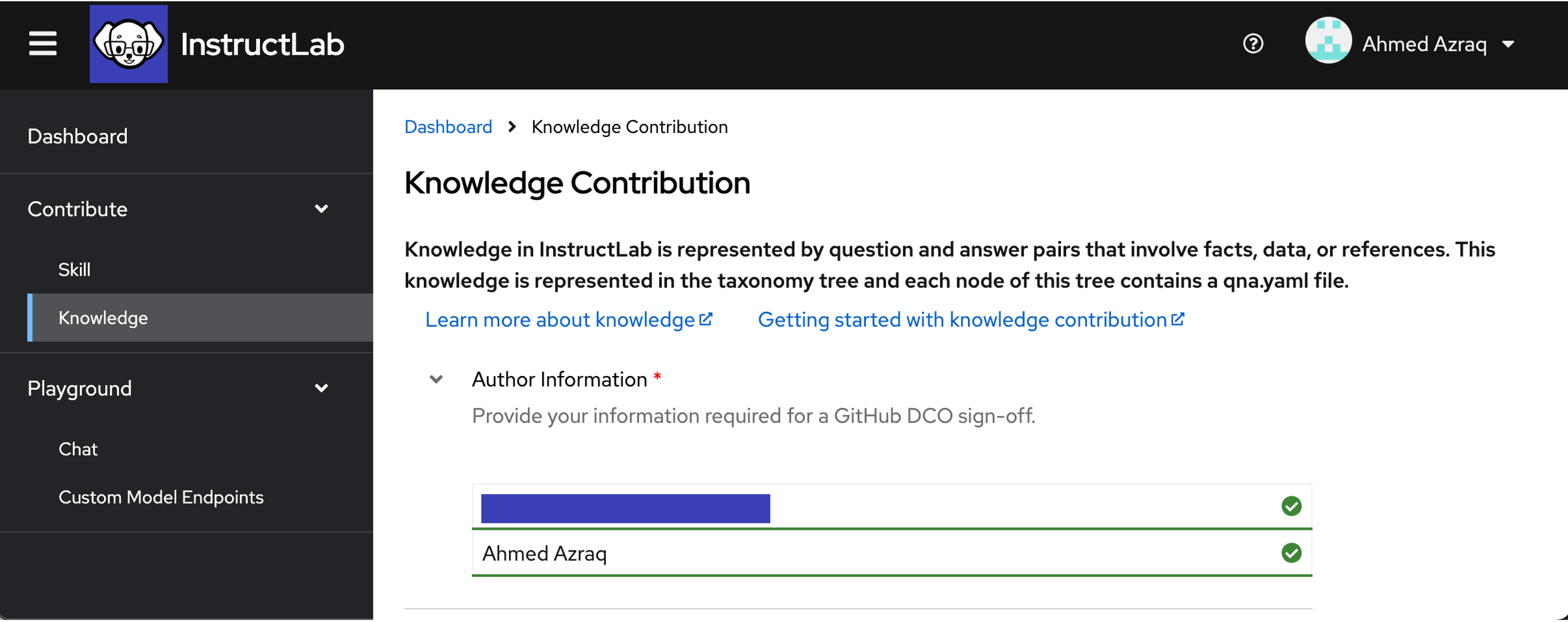
-
Enter more details about the knowledge being contributed, including a submission summary, domain, and document outline. In the first field, try to put a longer description, and notice that InstructLab UI limits it to only 60 characters.
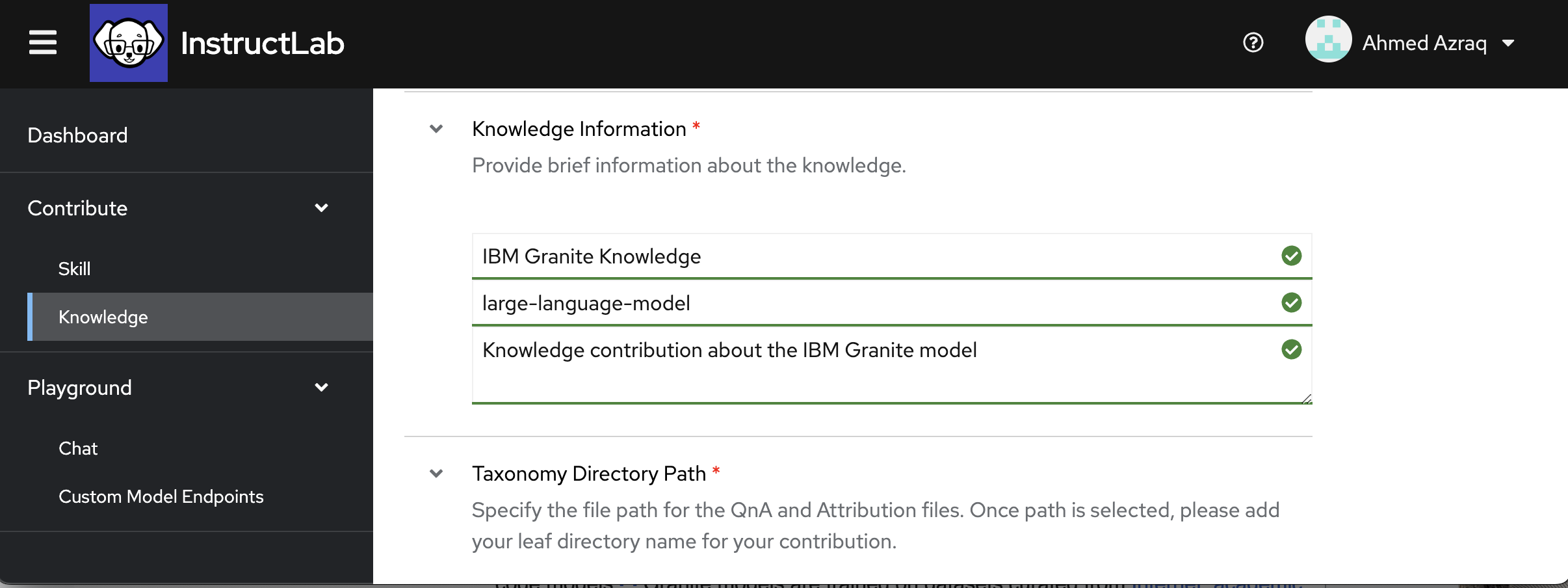
-
Specify the location in the taxonomy tree of your additional knowledge. You can navigate to the target location using the drop-down list. Once you choose your target directory, add the name of your subdirectory where you want your contribution to be stored. Make sure you use the subdirectory name that is relevant to your contribution. For example, specify technology/large_language_models/granite. This means that the output YAML file, qna.yaml, and the attributions file, attribution.txt, will be stored in this location in the taxonomy tree.
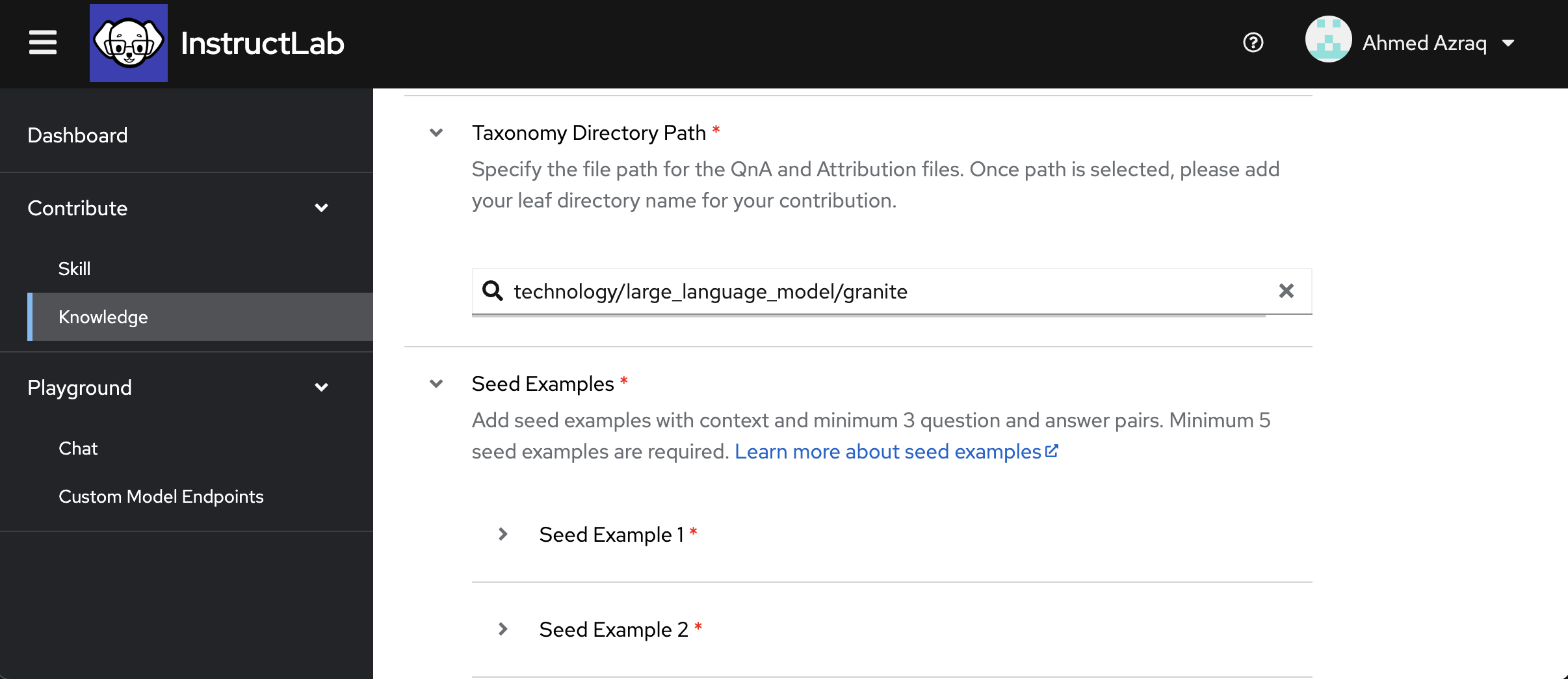
-
To contribute knowledge, you need at least 5 seed examples that will be used by the teacher model for synthetic data generation. Each example must have a context from the associated Markdown document, with at least 3 sample question and answer pairs.
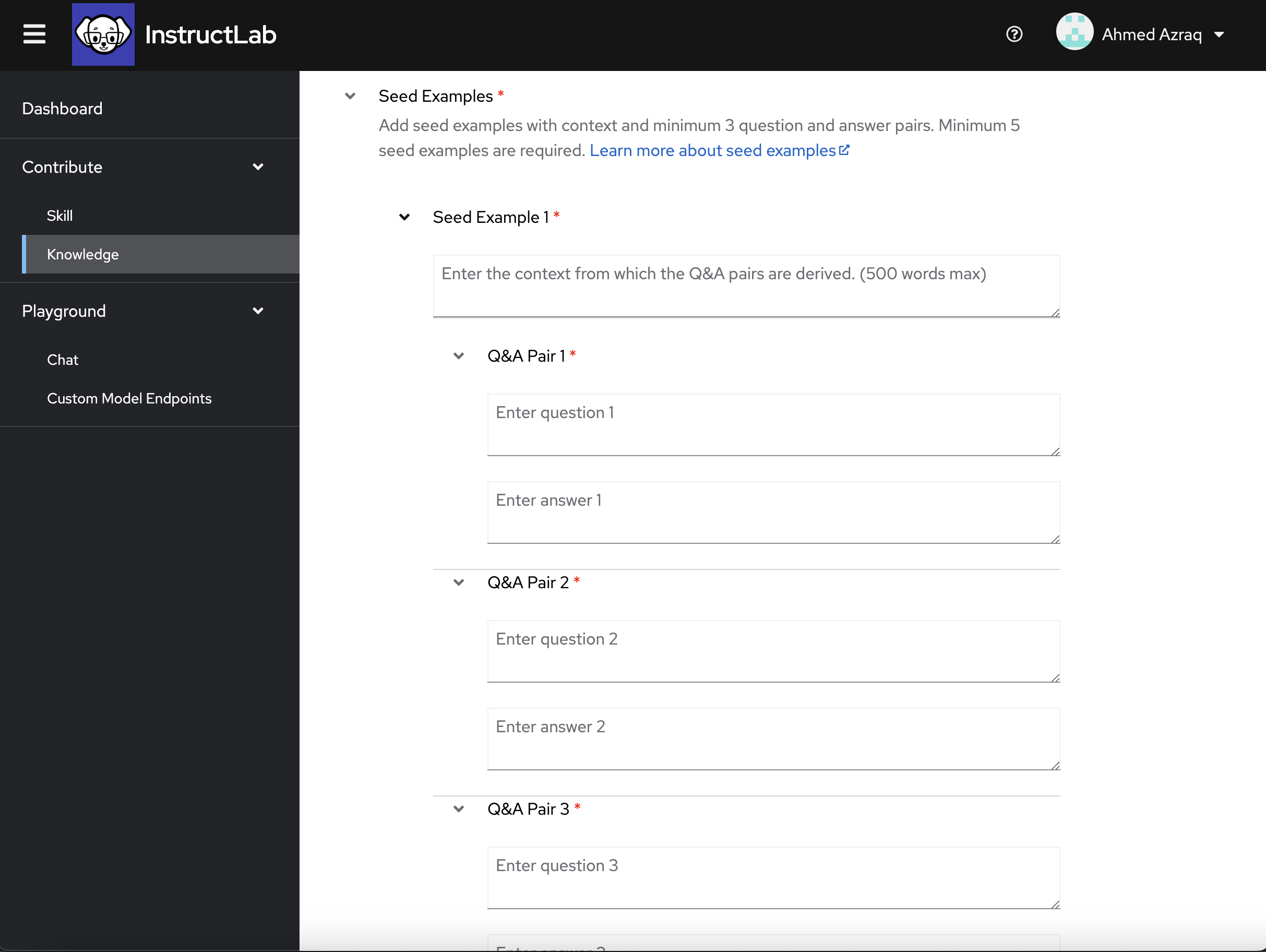
-
Fill the seed examples with context and associated 3 sample question and answer pairs as shown in the following screen capture.
-
For your convenience we’ve provided the seed examples below.
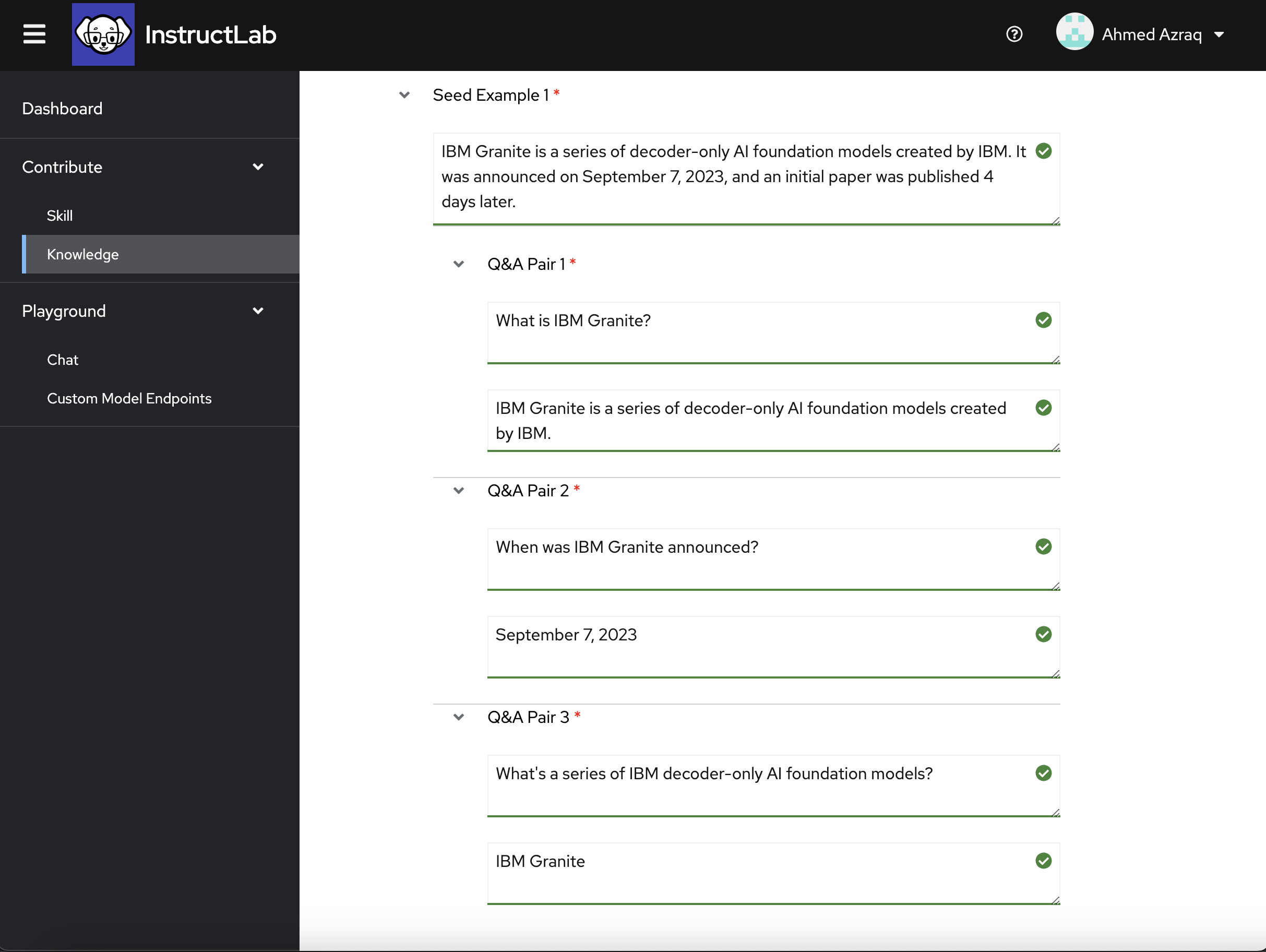
Seed Example 1
IBM Granite is a series of decoder-only AI foundation models created by IBM. It was announced on September 7, and an initial paper was published 4 days laterQ&A Pair 1 - Question
What is IBM Granite?Q&A Pair 1 - Answer
IBM Granite is a series of decoder-only AI foundation models created by IBMQ&A Pair 2 - Question
When was IBM Granite announcedQ&A Pair 2 - Answer
September 7, 2023Q&A Pair 3 - Question
When was the first paper about Granite publishedQ&A Pair 3 - Answer
On September 11, 2023, four days after Granite was announced.Seed Example 2
Granite's first foundation models were Granite.13b.instruct and Granite.13b.chat. The "13b" in their name comes from 13 billion, the amount of parameters they have as models, lesser than most of the larger models of the time. Later models vary from 3 to 34 billion parameters.Q&A Pair 1 - Question
What was IBM's first foundation models?Q&A Pair 1 - Answer
IBM's first foundation model were Granite.13b.instruct and Granite.13b.chatQ&A Pair 2 - Question
What does the 13b stand for in the Granite name?Q&A Pair 2 - Answer
It stands for 13 billion, the amount of parameters the model has.Q&A Pair 3 - Question
How many parameters do Granite models have today?Q&A Pair 3 - Answer
Today's Granite models have between 3 and 24 billion parameters.Seed Example 3
On May 6, 2024, IBM released the source code of four variations of Granite Code Models under Apache 2, an open source permissive license that allows completely free use, modification and sharing of the software, and put them on Hugging Face for public use. According to IBM's own report, Granite 8b outperforms Llama 3 on several coding related tasks within similar range of parameters.Q&A Pair 1 - Queston
Are the IBM Granite LLMs free to use?Q&A Pair 1 - Answer
Yes, IBM has made their Granite Code Models available as open sourceQ&A Pair 2 - Question
What type of licence does IBM Granite have?Q&A Pair 2 - Answer
IBM Granite has an open source permissive Apache 2 licence that means it is completely free to use.Q&A Pair 3 - Question
Where can you get a copy of IBM Granite?Q&A Pair 3 - Answer
On Hugging FaceSeed Example 4
Granite vision model is a pre-trained model specialised on vision tasks for document and image understanding, supporting a range of file types and resolutions, and designed for efficient deployment in enterprise environments. It can be used by individuals or large corporations.Q&A Pair 1 - Question
Does IBM Granite have a vision model?Q&A Pair 1 - Answer
Yes, IBM Granite has a vision model, called Granite vision modelQ&A Pair 2 - Question
What can the IBM Granite vision model do?Q&A Pair 2 - Answer
The IBM Granite model is trained on vision tasks for document and image understanding, supporting a range of file types and resolutions, and designed for efficient deployment in enterprise environments.Q&A Pair 3 - Question
Is the IBM Granite vision model for use by individuals or organisations?Q&A Pair 3 - Answer
IBM Granite is designed for enterprise environments, but can be used by individuals or companies.Seed Example 5
You can safeguard AI with Granite Guardian, ensuring enterprise data security and mitigating risks across a variety of user prompts and LLM responses, with top performance in 15+ safety benchmarks.Q&A Pair 1 - Question
What is Granite Guardian?Q&A Pair 1 - Answer
Granite Guardian safeguards your user prompts and LLM responses ensuring enterprise data security and mitigating risksQ&A Pair 2 - Question
How many safety benchmarks has IBM Granite been rated in?Q&A Pair 2 - Answer
15+Q&A Pair 3 - Question
What is the name of IBM Granites safeguarding capability?Q&A Pair 3 - Question
Granite Guardian -
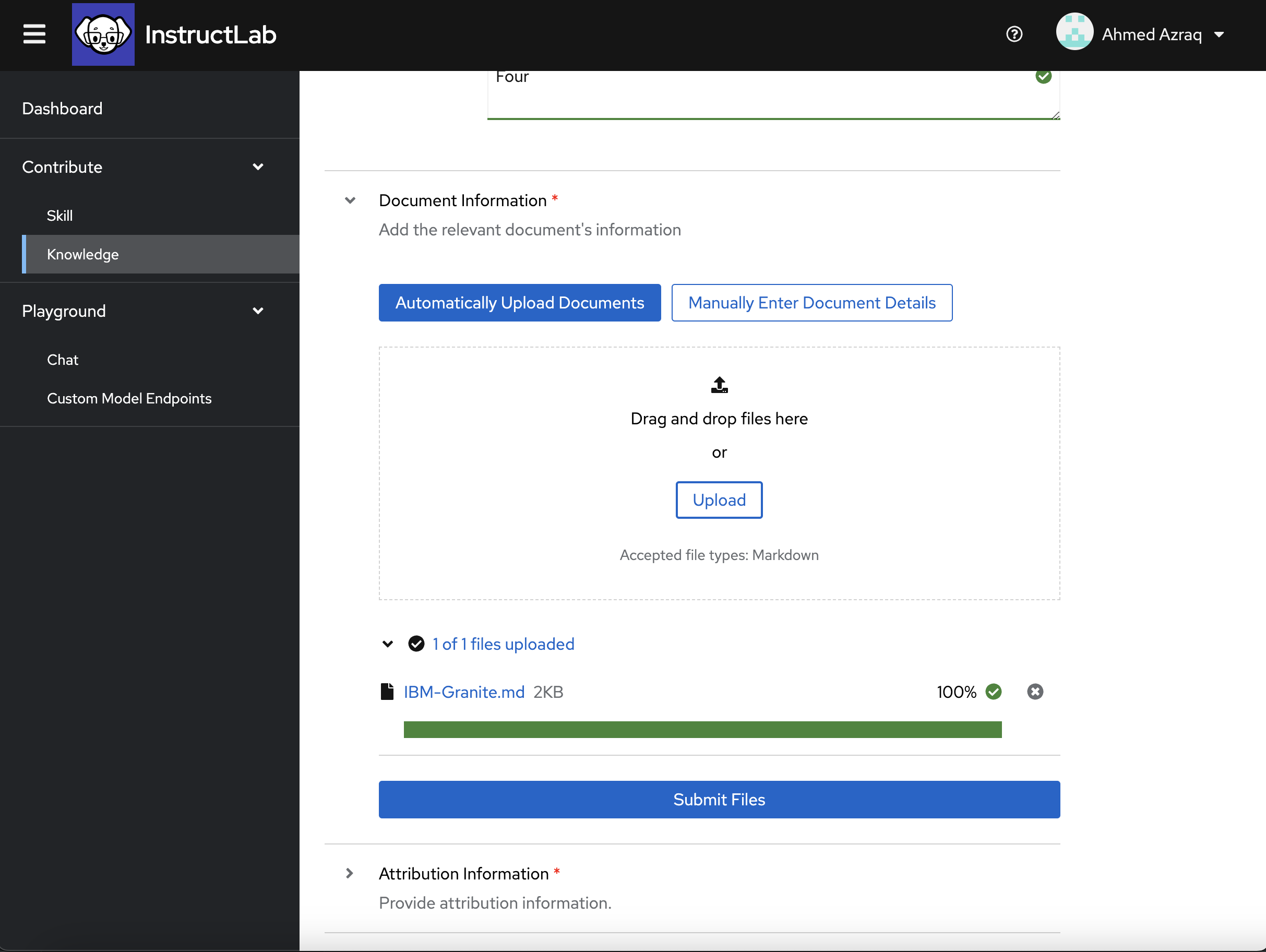
In the document information, upload the reference grounded knowledge that you prepared earlier as Markdown by clicking the Upload button and choosing the Markdown file, and then click Submit Files.
-
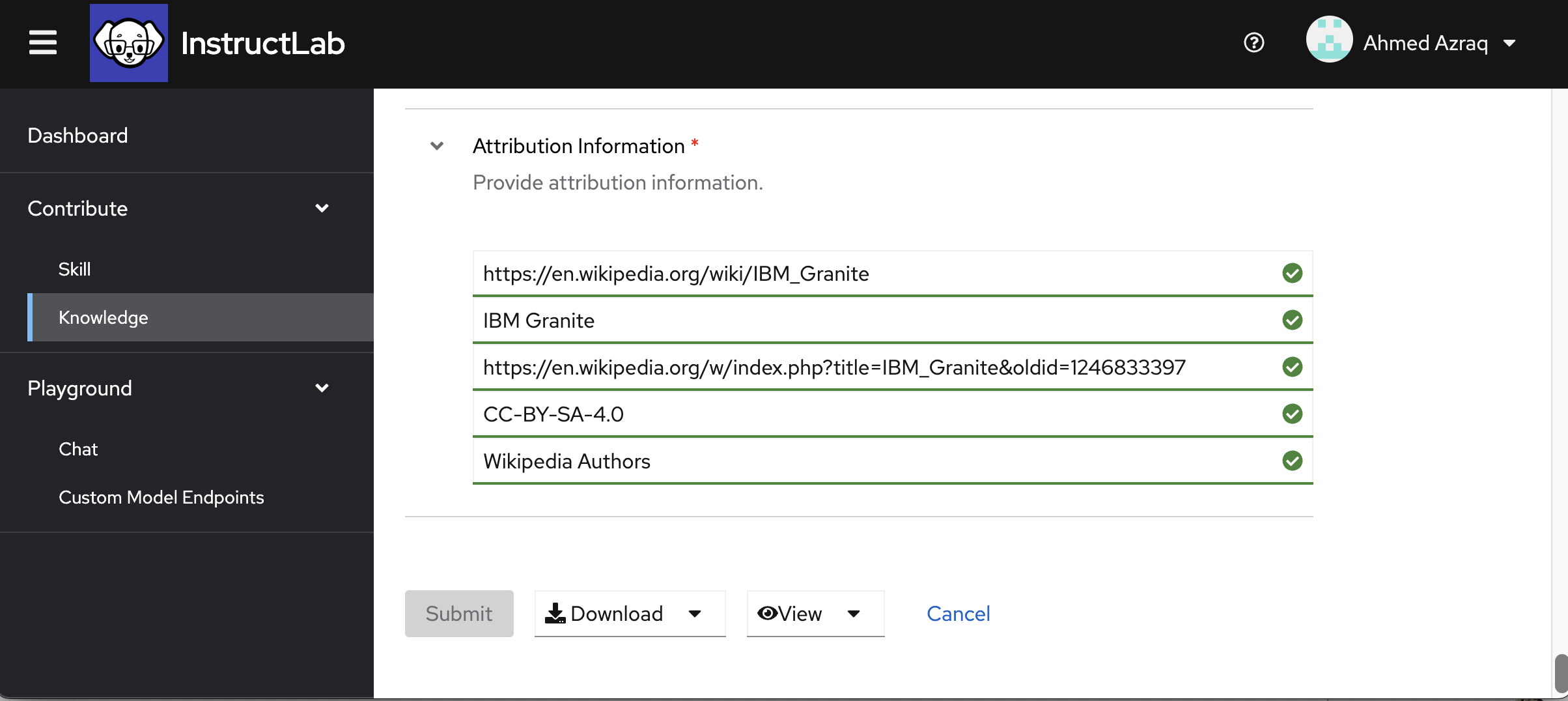
Fill in the attribution details with the actual link, including the knowledge, title of the knowledge, the specific revision used, license details of the knowledge being contributed, and the actual knowledge author.
-
Download the generated qna.yaml and attribution.txt files by clicking Download.
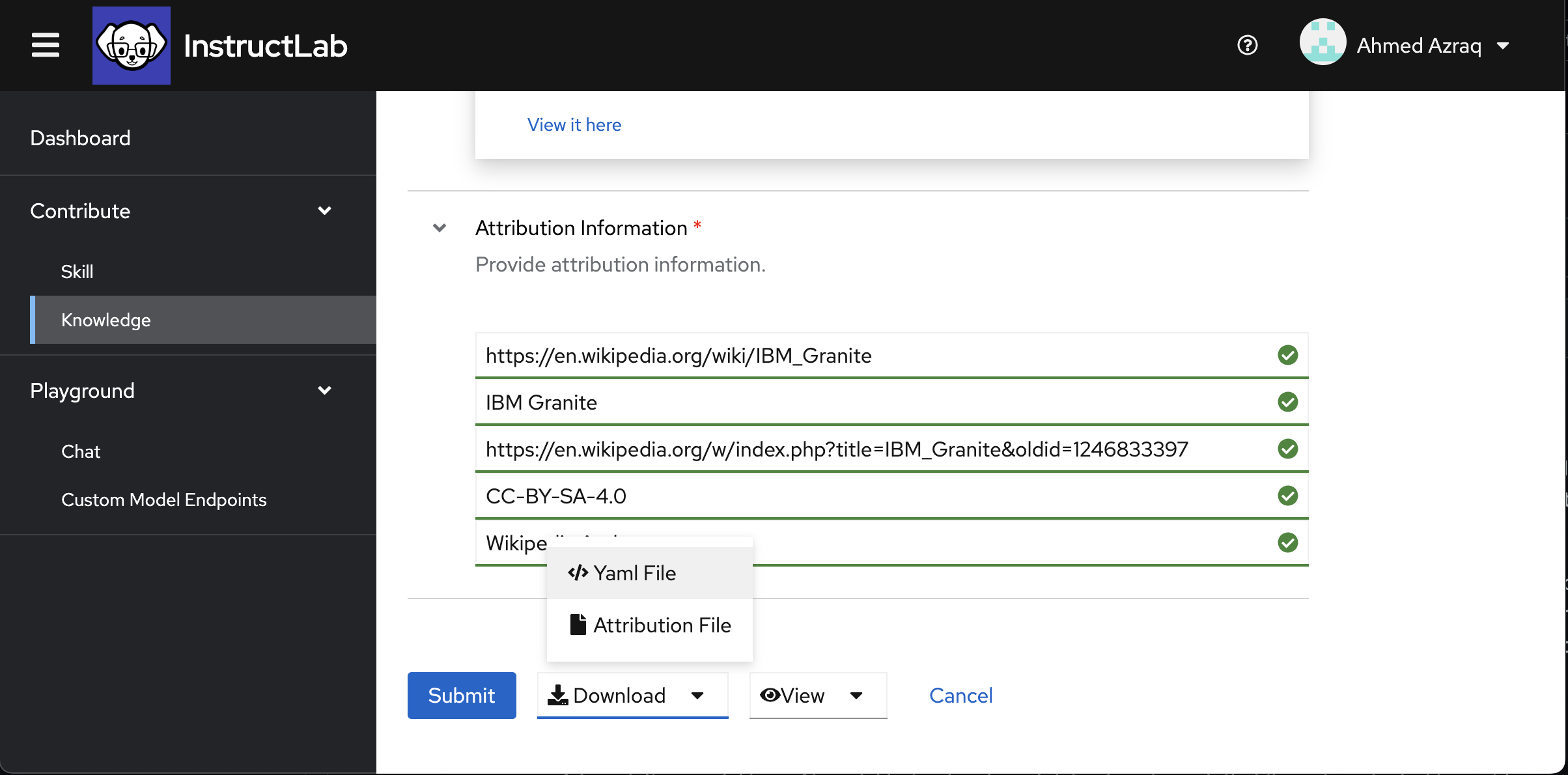
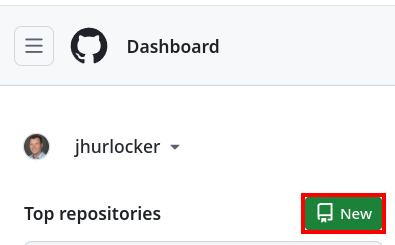
-
Create a repository in Github so we can upload our qna.yaml and attribution.txt files. Go to Github (make sure you’re logged in) and click the New button to create a new repository.
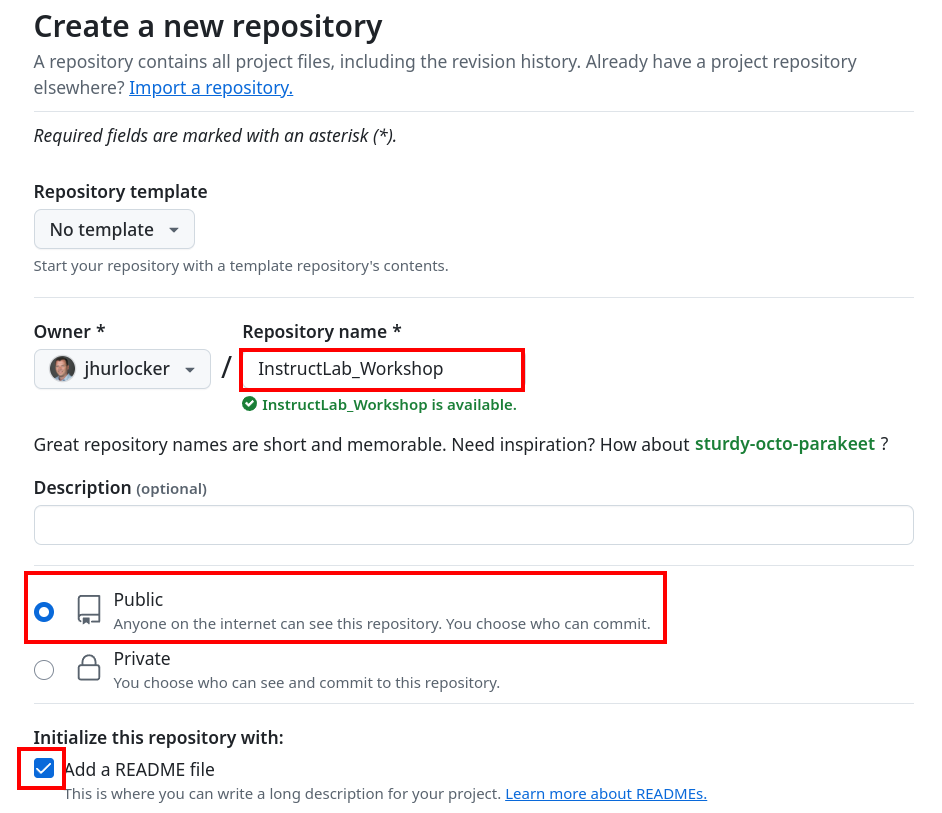
-
Give the repository a name of InstructLab_Workshop, make sure Public is selected, and select Add a README file. Scroll down and click Create Repository
-
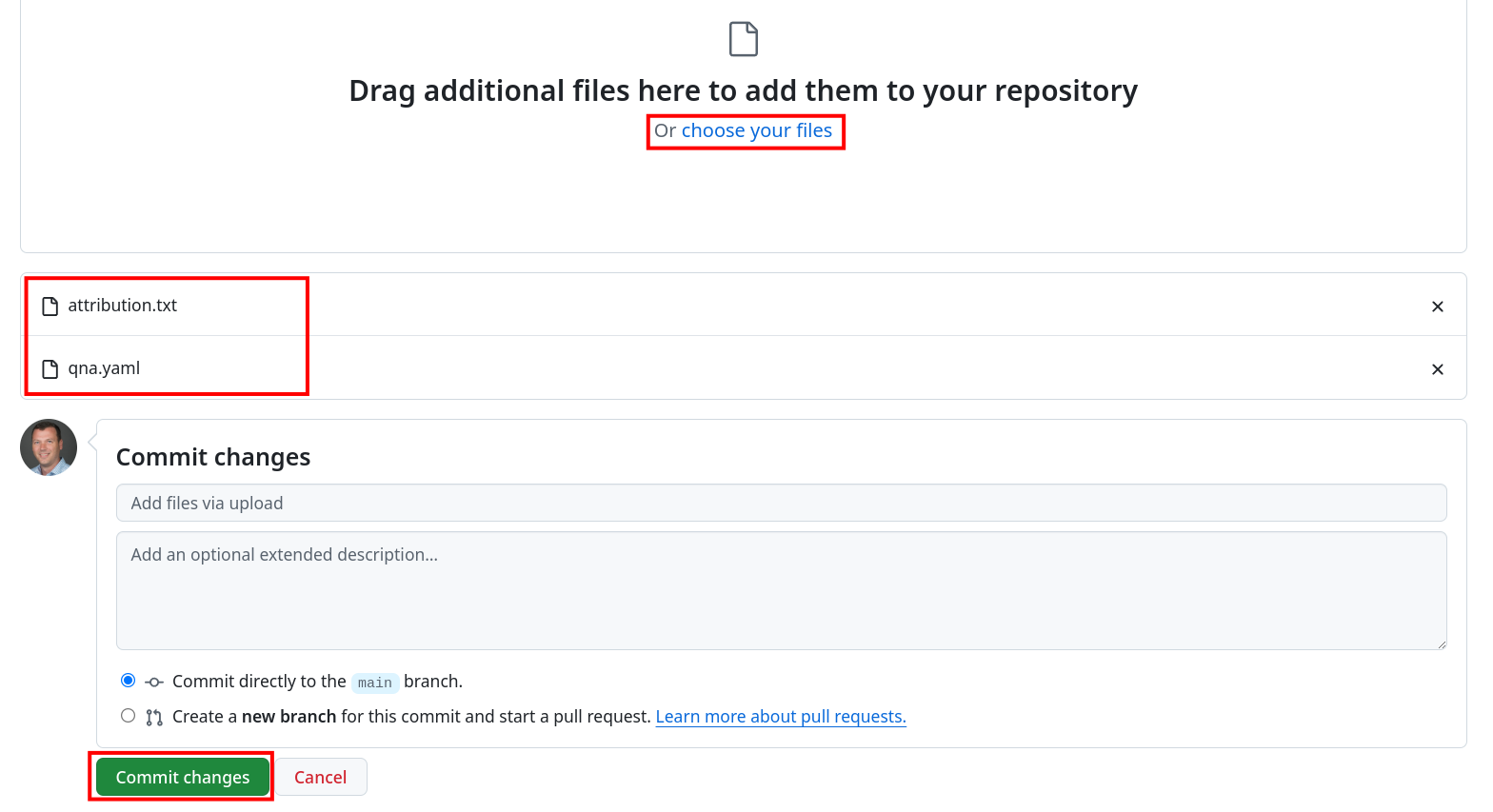
Click on the Add file dropdown and click Upload files
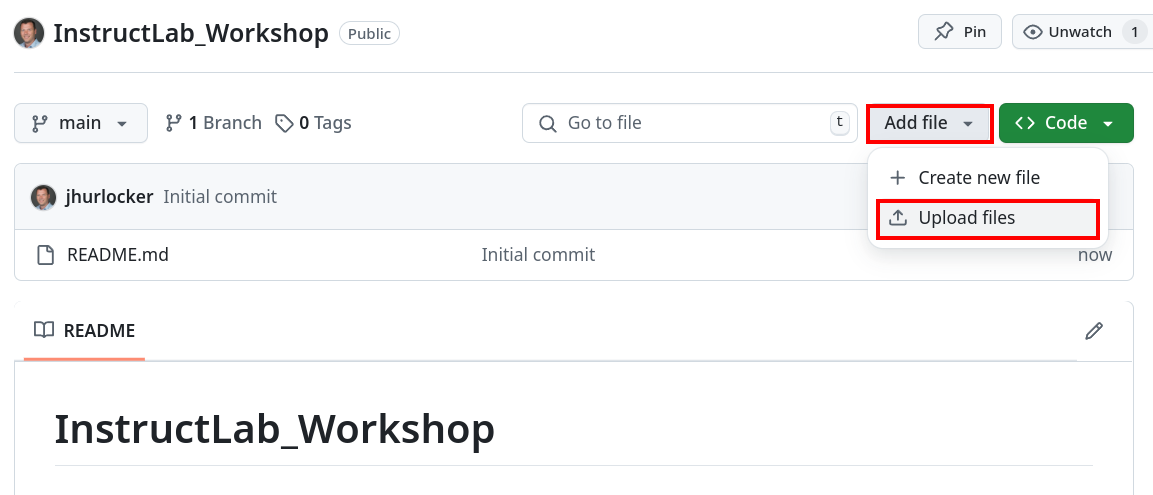
-
Upload the qna.yaml file and attribute.txt file you downloaded and click Commit changes.
Step 5. Train the model locally with the new knowledge
In this step, you will use InstructLab to train the model locally with the new knowledge. Check out this tutorial, Contributing knowledge to the open source Granite model using InstructLab, for more details on how to set up your local environment and run the entire process locally. This step assumes that you have already completed this other tutorial and have your local environment set up.
-
In the bottom terminal window navigate to InstructLab directory and clone your repository. To get your repository URL click on Code and then the copy button under HTTPS.
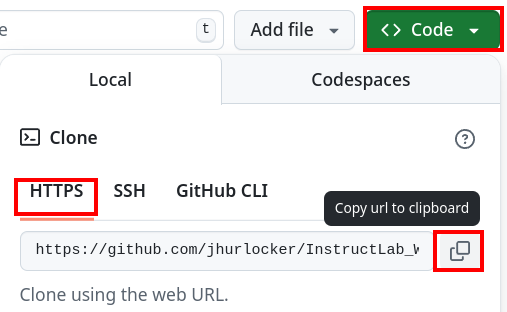
cd ~ git clone https://github.com/<YOUR_REPO> -
Create a new folder inside taxonomy to add the new knowledge.
mkdir -p taxonomy/knowledge/technology/large_language_model/granite -
Move the downloaded qna.yaml and attribution.txt files inside the newly created folder.
mv InstructLab_Workshop/attribution.txt InstructLab_Workshop/qna.yaml taxonomy/knowledge/technology/large_language_model/granite -
Verify that InstructLab detects the new taxonomy change you created and has a valid syntax. You should not worry about syntax errors here since InstructLab UI ensured that the generated taxonomy is valid.
ilab taxonomy diff#Output knowledge/technology/large_language_model/granite/qna.yaml Taxonomy in ./taxonomy is valid :) -
Generate synthetic training data. You can remove --pipeline simple argument in case you want to run the full pipeline for more accurate synthetic data generation, but this will take more time on a laptop. Also, you can specify the teacher model that has been downloaded earlier with ilab model download through --model argument. +
ilab data generate --pipeline simple
-
Train the model. Keep the default parameters if you want to train the Granite model as a student model. If you want to train the Merlinite model instead, pass the argument --model-path instructlab/merlinite-7b-lab. +
ilab model train --pipeline simple
-
If you want to run this locally on your Mac, convert the newly trained model into quantized model GGUF format +
ilab model convert --adapter-file "~/.local/share/instructlab/checkpoints/instructlab-granite-7b-lab-mlx-q/adapters-100.npz" --model-dir "~/.local/share/instructlab/checkpoints/instructlab-granite-7b-lab-mlx-q"
-
Chat with the newly trained model. This step automatically serve the new fine-tuned model identified in argument --model. +
ilab model chat --model instructlab-granite-7b-lab-trained/instructlab-granite-7b-lab-Q4_K_M.gguf
+ Now, the moment of the truth. Ask the new model question about the new knowledge contributed. Type an inquiry to the model What is IBM Granite? as shown below.
+ image::chat-response-trained-model.png[Download, 80%, 80%]
+ Notice that the trained model now identifies IBM Granite as a foundation model developed by IBM Research. The model might have some hallucinations because of using a quantized model running on a laptop with low resources for data generation, training, and inferencing. However, the improved accuracy of the response demonstrate that the IBM Granite model now is successfully trained on your knowledge contribution about "IBM Granite".
Step 6. Optionally, contribute the knowledge to InstructLab
In this final step, you learn how to contribute knowledge to the InstructLab taxonomy repo to improve LLMs. This an optional step; you can just read through it to understand the process so that you can follow it when you have actual knowledge or skills that you want to contribute to InstructLab.
You will use InstructLab UI to accomplish this step.
-
Go back to InstructLab UI browser window.
-
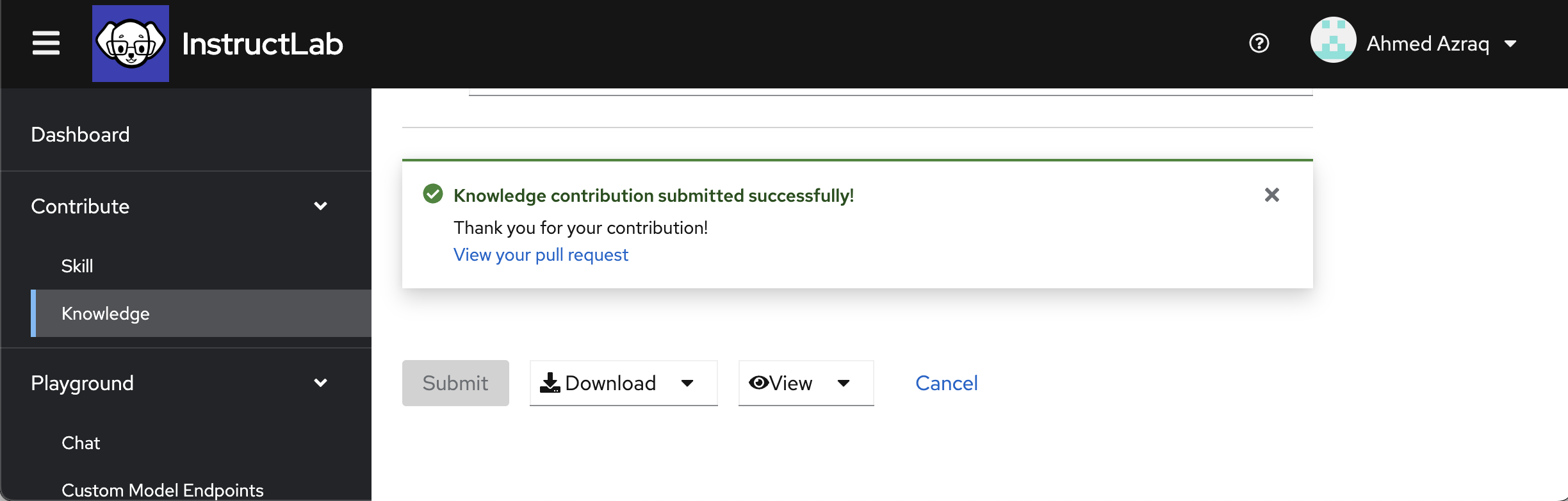
Click Submit to automatically open a pull request on the InstructLab taxonomy repository. You should receive a successful message as shown in the following screen capture after the successful submission.
-
Click View your pull request. Check out this sample Pull-Request
Summary and next steps
In this tutorial, you learned how to contribute to fine-tuning and improving LLMs such as the IBM Granite models using InstructLab UI.
+ Now that you’ve seen the power of InstructLab UI, check out Red Hat Enterprise Linux AI, which brings together the open source Granite family of LLMs, the InstructLab model alignment tools, a bootable image of Red Hat Enterprise Linux, including popular AI libraries such as PyTorch, and enterprise-grade technical support and open source assurance legal protections. Then, you can scale your AI workflows with Red Hat OpenShift AI and begin using IBM watsonx.ai, which provides additional capabilities for enterprise AI development, model governance, enterprise workflows around advanced data ingestion, data lineage, governance, and model evaluation capabilities.
Acknowledgments
This tutorial is produced as part of an IBM Open Innovation Community initiative.
+ The author appreciates the efforts of Anil Vishnoi (Principal Software Engineer, Red Hat), Susan Malaika (Senior Technical Staff Member, IBM), and Suhas Kashyap (Senior Product Manager, InstructLab for watsonx.ai, IBM) for their guidance and expertise in reviewing and contributing to this tutorial.