Fix Virtual Machine is not starting
Scenario
The user tried to deploy and run a virtual machine and is facing an issue.
The primary goal in this scenario is to investigate the cause of the failure and take corrective action to get exercise2 virtual machine back into the Running state.
|
The steps to fix exercise2 are:
Console
-
Login to Openshift console using the assigned user account
userx{password}-
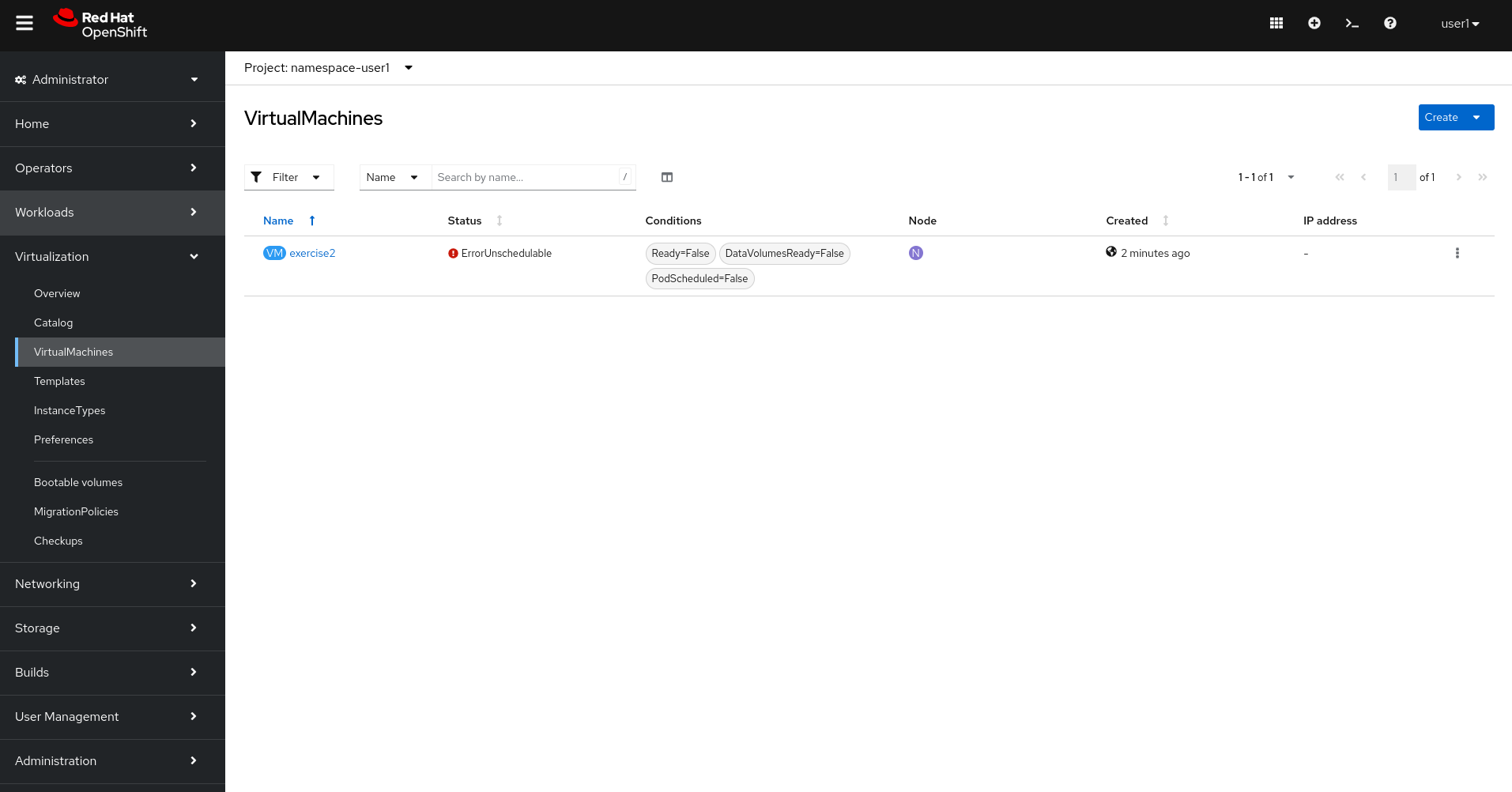
Go to Virtualization - Virtual Machines and check the VM status.
-
Check the Virtual Machine is failing with error
ErrorUnschedulable.
-
Go to tab
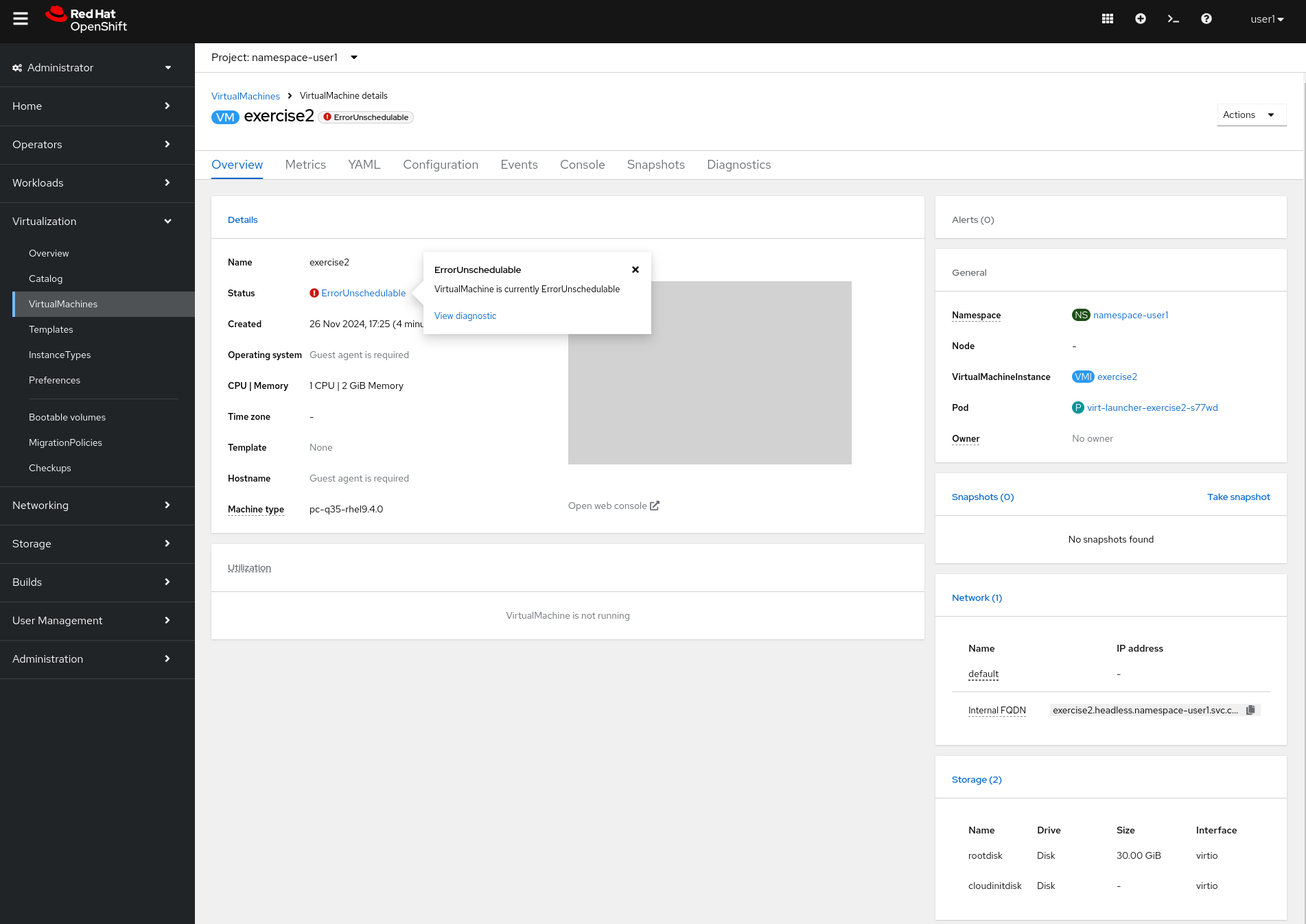
YAMLand check the status of the Virtual Machine. It is failing with error message:
message: '0/6 nodes are available: 3 node(s) didn''t match Pod''s node affinity/selector, 3 node(s) had untolerated taint {node-role.kubernetes.io/master: }. preemption: 0/6 nodes are available: 6 Preemption is not helpful for scheduling.'-
Check the
NodeSelectorandTolerationsassigned to this virtual machine.
nodeSelector:
node-role.kubernetes.io/baremetal: ''
tolerations:
- effect: NoSchedule
key: bare_metal
value: 'true'-
These
NodeSelectorsandTolerationsrefer to nodes that do not match those in the cluster. Remove them.
-
Restart the virtual machine to apply the changes.
-
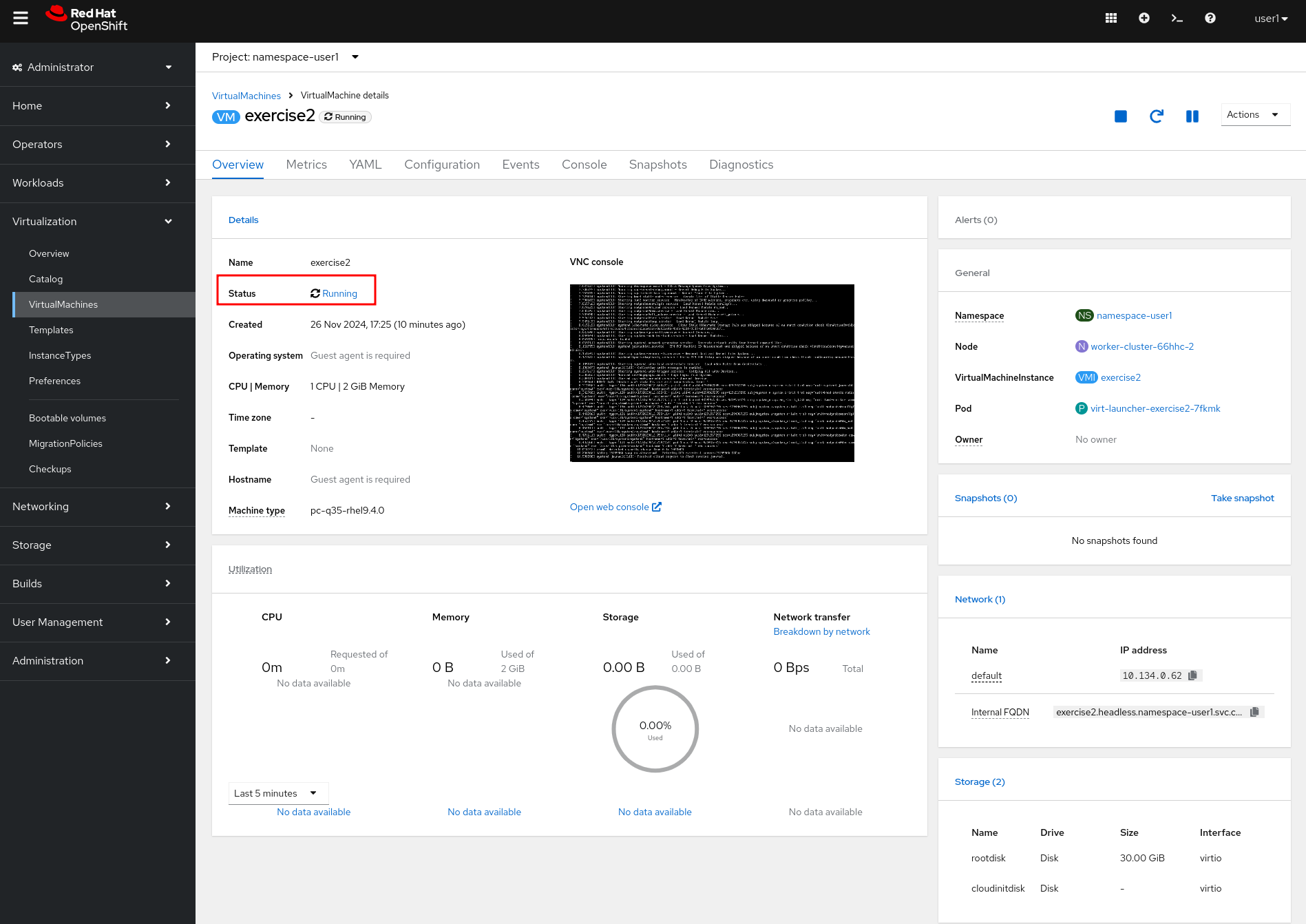
Wait for the virtual machine to start and check that now the virtual machine is in
Runningstate.
lab grade exercise2Command line (CLI)
-
Login to Openshift server API using the assigned user account with
occommand if not logged in.
{login_command}-
Go to the assigned namespace-userx
oc project namespace-userx-
Check there is a virtual machine running in this namespace and it’s status. The output should be similar to the following one:
oc get pod,vmNAME READY STATUS RESTARTS AGE pod/virt-launcher-exercise2 0/1 Pending 0 19s NAME AGE STATUS READY virtualmachine.kubevirt.io/exercise2 20s ErrorUnschedulable False
-
Check which the the Virtual Machine status to get more details about the error:
oc describe vm exercise2Status:
Conditions:
Last Probe Time: 2024-11-26T16:38:19Z
Last Transition Time: 2024-11-26T16:38:19Z
Message: Guest VM is not reported as running
Reason: GuestNotRunning
Status: False
Type: Ready
Last Probe Time: <nil>
Last Transition Time: <nil>
Message: Not all of the VMI's DVs are ready
Reason: NotAllDVsReady
Status: False
Type: DataVolumesReady
Last Probe Time: <nil>
Last Transition Time: 2024-11-26T16:38:19Z
Message: 0/6 nodes are available: 3 node(s) didn't match Pod's node affinity/selector, 3 node(s) had untolerated taint {node-role.kubernetes.io/master: }. preemption: 0/6 nodes are available: 6 Preemption is not helpful for scheduling.
Reason: Unschedulable
Status: False
Type: PodScheduled
Created: true
Desired Generation: 1
Observed Generation: 1
Printable Status: ErrorUnschedulable
Run Strategy: Always
-
Inspect the virtual machine and check the
NodeSelectorandTolerationsassigned to this virtual machine.
oc get vm exercise2 -oyaml nodeSelector:
node-role.kubernetes.io/baremetal: ''
tolerations:
- effect: NoSchedule
key: bare_metal
value: 'true'-
These
NodeSelectorsandTolerationsrefer to nodes that do not match those in the cluster. Edit the virtual machine configuration file and remove them.
oc edit vm exercise2-
Restart the virtual machine
virtctl restart exercise2-
Wait until the virtual machine is started and make sure it is in
runningstate
oc get pod,vmNAME READY STATUS RESTARTS AGE pod/virt-launcher-exercise2 1/1 Running 0 40s NAME AGE STATUS READY virtualmachine.kubevirt.io/exercise2 5m9s Running True